Overview
Introduction and Background
Our project revolves around identifying the breeds of dogs in images. Our project consists of four components, all of which are individual methods of classifying dog breeds: using a neural network, using transfer learning, and using KMeans to sort the data into clusters with and without feature descriptors. Our primary goal of the project is to produce an unsupervised learning algorithm that performs comparably to our supervised learning algorithms. There are three datasets currently in use, all of which contain pictures of dogs along with labels of their corresponding breeds. In addition, one provides splits for how the data was originally used as training data, testing data, or validation data.
Problem Definition
The purpose of this project is to investigate the effectiveness of methods we are learning in class with classifying dog breeds. In particular, we wish to compare standard supervised learning methods in their accuracy and efficiency to unsupervised learning methods relying on feature detection of the input images.
Data Exploration and Cleaning
Data Exploration
To approach the problem, we used public datasets provided by Stanford and Tsinghua. The Stanford dataset consists of a total 20580 number of dog pictures for 120 breeds of dogs. Tsinghua dataset consists of a total 70428 number of dog pictures for 130 breeds of dogs. Tsinghua dog data annotated bounding boxes of the dog’s head and body in each image, which is useful for learning algorithms and testing. The below figure shows a sample type of dog breed.


Variation in Stanford Dogs dataset. Border collie and English springer
Data Cleaning
Since we found datasets that have text labels with different spaces and capitalizations, we needed to clean texts and make the labels uniform. We needed to get rid of the spaces and capital letters involved. To do so, we converted the text labels into an excel spreadsheet and preprocessed the labels.
Supervised Learning Models
Method 1
For Method 1 we decided to implement a convolutional neural network with the Kaggle dataset. The CNN we created has 4 different types of layers: Convolutional Layer: This layer consists of a number of filters which pick up different types of features. Each filter steps through the whole image and learns a feature such as shape of a dog’s ear. Pooling Layer: It is used to take large arrays and shrink them down. Max pooling takes the max value of pixels over a region and average pooling takes the average value. Dense or Flatten Layer: This layer converts the input array into a 1-dimensional array, where each value is a probability of the image belonging to a certain class. Activation functions are used to either activate or deactivate a weight in the CNN. The most popular one for CNNs is ReLU or some variation of it. Dropouts were used to decrease overfitting and help remove dead weights during training.
Here is a summary of our final model: The total number of parameters in this model is equal to the number of trainable parameters, which will not be the case with transfer learning.

Tweaking the model and hyperparameters
The initial image dimensions were 224x224x3. With these images, we first constructed a 2 layer model which gave us an accuracy of ~11% before starting to overfit. When 3 layers were added, the accuracy was around ~13%. With 4 layers we were able to raise the accuracy to 20% before seeing overfitting. With 5 layers there was overfitting around 17%. We understood that accuracy is not the most useful metric to evaluate the model, so we only used it for some preliminary testing to figure out optimal number of layers and dimensions and augmentations of images that would give best results. The final model’s performance against test data was evaluated using the metrics precision, recall, and f1 score.

Results and Discussion
To preprocess our data, we used OpenCV. Once we figured out that the optimal number of layers was four, we resized the images to different dimensions to see which would give the best results. We also needed to perform one hot encoding before feeding the data into the model. We found that scaling down the images by a factor of 0.4 increased our accuracy to ~47% before starting to over-fit. The metrics used to evaluate the model are:
Accuracy = TP+TN/TP+FP+FN+TN
Precision = TP/TP+FP
Recall = TP/TP+FN
F1 Score = 2*(Recall * Precision) / (Recall + Precision)
Where TP = True positives, FP = false positives, FN = false negatives, TN = true negatives. These metrics for our model are shown below.
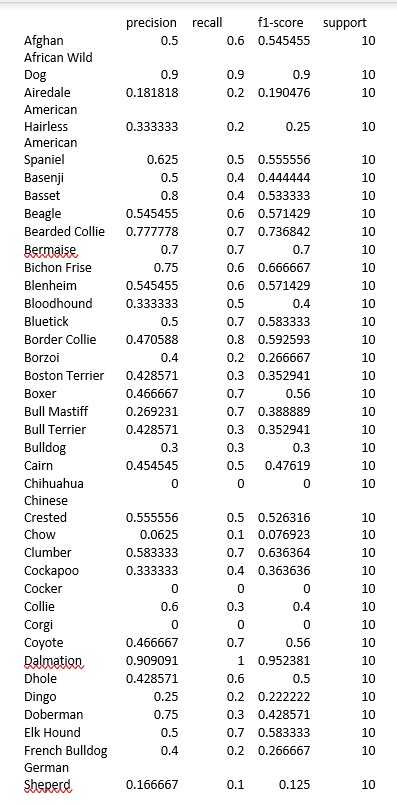
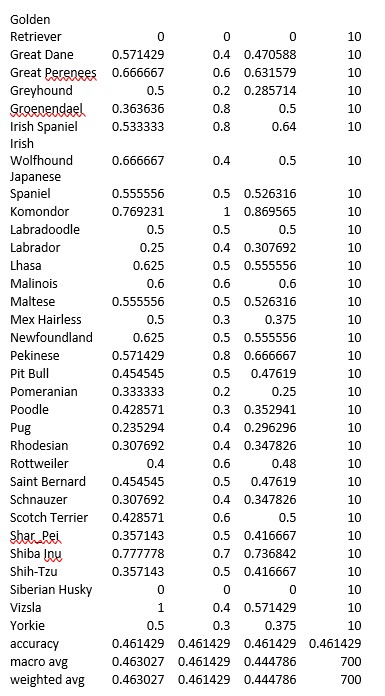
The next step will be to evaluate which transfer learning will be best for our application.
Unsupervised Learning Models
Dealing with the data
For an unsupervised model, we need to somehow “standardize” the data. “Standardize” here refers to transforming all the images in a standard format, where all the images are of the same size so that we can compare each image with each other. The problem with many image dataset (even here with Tsinghua dataset and Stanford dataset of dog images) is that images are not of a standard size. In order to convert them into a standardized size, we will need to perform a reshape operation on each of the images. The operation in itself is very easy, BUT we must remember throughout our experiment that due to this operation, we will lose some of the knowledge that we can obtain from the original image - for example, if we are doing this reshape operation on an image that is of a larger size and is not of the aspect ratio of the target size, we will lose a lot of knowledge about the shape of the features of dog from the image, as the image may be distorted. Hence, when we compare our results, we must keep these transformations and the reduction in the data from our datset in our mind.
Model 1 - The Naive Way (KMeans on unfiltered data)
The simple way to apply an unsupervised learning algorithm on a dataset is to simply perform a “KMeans on the reshaped images using sum-squared errors as the loss function”. As simple as it sounded in our heads at the start, when we started on this model, we came across a lot of issues why this is the wrong way.
Finding if this model is feasible
In order to first analyze whether just calculating a simple sum-squared error will work or not, we tried finding the errors between images of the same breed, and then images of the different breed, and seeing whether these errors have a certain pattern. The motivation behind this exercise was to see if there are certain thresholds OR some patterns with the sum-squared loss that we can utilize in order to concretely perform KMeans on dog images between different breeds.
So, we started by calculating the errors within images of the same breed, and seeing what errors do they throw. The method was slow, but there was no other way. Here is the algorithm that we used -
- Get all the reshaped images (224x224x3) of the same breed into a one big Numpy array.
- Perform a
O(N^2)for-loop for finding errors between each images. - Plot a boxplot of these errors in order to visualize them.
The results of these boxplots of the 120 breeds in the Stanford dataset can be seen here - https://drive.google.com/drive/folders/1eDCdK_ckpxzjd9K4ZXuoDaNJ2Rzcztu8?usp=sharing. The average error of all the breeds can be seen in this image (values are normalized to a scale of 0-1) -
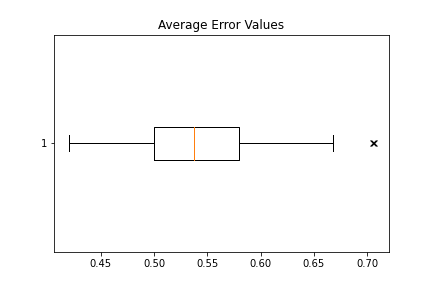
But before we could move onto capturing patterns from this data OR calculating errors between images of different breeds, we ran into some of the problems, which we explain in the next sub-section.
Problems
- The above algorithm gave us our first big problem - Memory Overflow. Instead of the for-loop in the 2nd step of the algorithm, we tried a faster way by using Numpy broadcasting. But the data was so huge for our code, the broadcasted array could not fit into memory. Hence, we had to utilize a for-loop instead of broadcasting.
- Because of using a for-loop, this step became excruciatingly slow. To calculate intra-breed errors of 130 breeds, the algorithm deployed on a Google Colab instance took 4.5 hours to complete. With this, we realized that performing such an analysis for inter-breed error calculation will be very time consuming.
With the above 2 problems, it was clear that there is a desperate need of feature engineering OR feature reduction that will need to be performed on the datset before we can continue on our journey to image clustering goal.
Model 2 - Maybe CV can save us? (KMeans using SIFT descriptors)
Since there was a need of feature reduction, we turned to the idea of detecting features in image. Subsequently, Computer Vision algorithms came to our mind. There are multiple image feature descriptors (as has been outlined in this great OpenCV documentation - https://docs.opencv.org/4.x/db/d27/tutorial_py_table_of_contents_feature2d.html). Choosing the correct one becomes an important descision. Knowing not much about Computer Vision, we were struck by the SIFT (Scale-Invariant Feature Transform) descriptors. As you may recall from our initial warning about the dataset, we need to reshape OR rescale our dataset images to a standard scaling in order to compare images and their features for unsupervised learning algorithms. Having SIFT saves our assumption of caring about, how scale changes the accuracy of the dataset. Hence, SIFT immediately became a strong choice for the model.
SIFT (Scale-Invariant Feature Transform)
We will not go into immense details on how SIFT works and how it detects each features (frankly, we ourselves are not an expert at CV, but were a bit mesmerized by how the math works behind it). But we still want to give the reader a brief description of what SIFT needs as an input and what it gives us as an output. The reader can treat the SIFT algorithm as a blackbox, as long as he/she understands what is gained from applying such an algorithm.
In essence, the SIFT algorithm takes in an image and gives us a list of key descriptors (could be corners in the image, straight lines, normal patterns, etc.) for the image. It calculates these descriptors in a 4-step process (https://docs.opencv.org/4.x/da/df5/tutorial_py_sift_intro.html) and then these descriptors can be used to match another image using a feature matching algorithm (can be as basic as applying sum-squared function).
Our goal is to take these descriptors and use it as a feature set for our KMeans algorithm
The Warmup
To test our theory of whether SIFT image descriptors could help us with our image clustering, we took a sample dataset of three breeds out of the Stanford Dog Dataset and applied our model to the images classified in these 3 breeds. Since we were facing a lot of performance issues and memory issuess in our first model, this time we chose to run our model on GPUs, which also meant a steep learning curve on PyTorch.
In the end, having had some inkling of how to interact with PyTorch tensors, we finally built a small warm-up model. Our model performs the following -
- Uses the PyTorch Dataloader functionality to lazy-load the image dataset into batches of 32 images.
- Then applies the SIFT Feature Descriptor algorithm on them to extract features from them.
- Compiles these Feature Descriptor into a one big tensor.
- This big tensor is then put through the Scikit’s KMeans algorithm implementation as Numpy arrays.
Using these three breeds as our initial dataset, here is what we came up with -
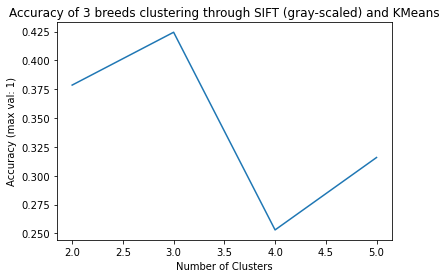
As you can see the accuracy is not really great. Although the positive point is that it is able to get the highest accuracy in the right number of clusters. This is definitely a positive sign. So, we started adapting our model to perform this matching on the whole Stanford dogs dataset.
But, Problems again…
While trying to apply this model on the whole Stanford Dogs Dataset, we again ran into issues where the combined tensor of the feature descriptors could not be loaded into the memory. This has been a great road-block for us, and now we are thinking of other ways to tackle this problem.
What’s Next? - Techniques and Models
One big problem that we have been dealing with is the memory issue. Our next steps to tackle this problem are as follows -
- Investigate if we can save tensors to disk storage and then load them for unsupervised learning algorithms.
- Investigate into creating or finding an unsupervised learning algorithm which can work on batch dataset. This will help us segment the whole datset into batches and then apply the algorithm on these batches.
Also, after learning about Neural Networks (NN) and Convolutional Neural Networks (CNN) in the class, we have come up with an idea of 2 other models -
- Using NN as our unsupervised learning algorithm, where we change the activation function to a regression function in the last layer which gives us a vector of the result of passing an image through the NN.
- Using CNN (or just the convolutional part) for feature reduction on images, and then using the same with normal unsupervised learning algorithms.
References
- https://datascience.stackexchange.com/questions/48642/how-to-measure-the-similarity-between-two-images
- http://slazebni.cs.illinois.edu/spring17/lec09_similarity.pdf
- https://towardsdatascience.com/image-clustering-implementation-with-pytorch-587af1d14123
- https://riptutorial.com/scipy/example/20970/image-manipulation-using-scipy–basic-image-resize-
- https://docs.opencv.org/4.x/dc/dc3/tutorial_py_matcher.html
- https://docs.opencv.org/4.x/da/df5/tutorial_py_sift_intro.html
- https://docs.opencv.org/4.x/db/d27/tutorial_py_table_of_contents_feature2d.html
- https://medium.com/data-breach/introduction-to-feature-detection-and-matching-65e27179885d